














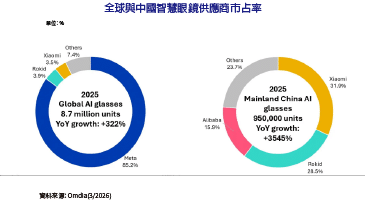
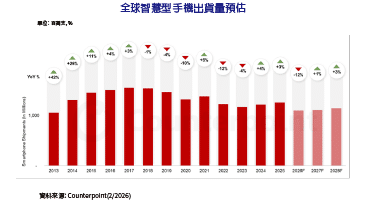
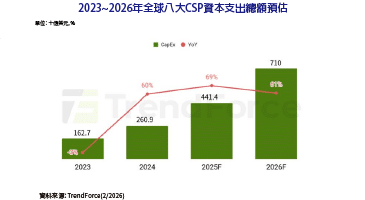
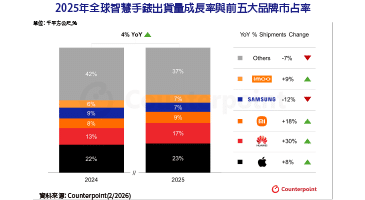





回顧無人載具的發展史,我們長期處於「自動化」階段,這時期的載具像是一個乖巧但死板的工廠作業員,沿著預設的GPS軌道或高清地圖(HD Map)行駛。一旦遇到地圖沒更新的施工路段,或是訊號遮蔽的騎樓死角,它們就會陷入癱瘓。
但邁入2026年,技術場景將發生本質上的轉變:載具開始具備「直覺」。它們不再需要保母式的地圖餵養,而是學會像人類一樣,靠著眼睛與大腦在陌生環境中穿梭,不僅要能自主判斷路況、決定方向,更要能在此狀況下成功到達目的地。

感知升級 從像素到語義
要讓機器在複雜城市中生存,首先得升級它的感官。過去的感測器大戰往往聚焦在「光達(LiDAR)與攝影機」的路線之爭,但現在產業已經走向了更高維度的「感測融合」。
2026年的主流感測方案,核心在於4D成像雷達與視覺模型的深度整合,4D光學雷達解決了光學鏡頭在豪雨、濃霧或逆光下的致盲問題,並提供了關鍵的「都卜勒速度」資訊,也就是說,它能瞬間判斷路邊的小孩是準備衝出來還是靜止不動。
更重要的是Transformer模型在感知層的主導能力,傳統演算法看世界是幾何學的,它看到的是一堆點與線;而引入多模態大模型後,載具開始具備「語義理解」能力。當無人配送車看到前方有人揮手,它不再只是偵測到「動態障礙物」,而是能理解這可能是「交警指揮」或「客戶招呼」。這種從幾何到語義的跨越。是機器能夠融入人類社會運作的入場券。
導航瘦身 擺脫地圖依賴症
導航技術正在經歷一場「去地圖化」的瘦身運動,過度依賴公分級高清地圖已被證明是商業模式的死穴,因為道路每天都在變,維護地圖的成本高得驚人。
新一代的導航邏輯轉向了「感知優先」與「記憶導航」。視覺慣性里程計(VINS)技術已臻成熟,它讓載具像老司機一樣,具備空間記憶能力。配合語義SLAM(即時定位與地圖構建)技術,無人機在進入GPS訊號全無的室內倉庫或地下停車場時,能透過識別「出口標誌」、「貨架特徵」來自我定位。

這就像是你去一個陌生城市,不需要一直盯著Google Maps的藍點,而是記住「看到紅色郵筒右轉。經過星巴克左轉」。這種模仿人類認路邏輯的導航方式,讓載具徹底擺脫了對GPS與圖資的絕對依賴,真正實現了全場景的自由移動。
決策變革 端到端直覺駕駛
最激動人心的變革發生在決策層,傳統自駕軟體架構那種「感知—預測—規劃—控制」的模組化切分,正在被「端到端」(End-to-End)大模型取代。
模組化架構就像大公司的科層體制,感知部門把人看成樹,預測部門就跟著錯,層層傳遞導致決策延遲與失誤。而端到端模型(如UniAD或特斯拉推崇的FSD v14架構)則是將攝影機輸入的原始影像,直接映射到油門與方向盤的輸出。
這意味著載具不再是依靠寫死的「若X則Y」程式碼規則在開車,而是透過學習數十億公里的人類駕駛影片,提煉出駕駛「直覺」。當遇到一個並排違停的複雜路況,傳統程式可能因為違反規則而卡在原地,但端到端模型能像人類一樣,壓過雙黃線借道超車。這種「類人」的模糊決策能力,是無人載具從封閉園區走向混亂市區的關鍵。
訓練與機會 數據助台灣AI轉型
既然要訓練大腦,數據就成了新石油。但真實世界的車禍與極端案例太少,數據蒐集太慢,2026年的產業競爭焦點,將轉移到「世界模型」(World Models)與生成式AI模擬器。

利用類似Sora的影片生成技術,開發者可以創造出無限逼真的虛擬世界。我們可以要求AI生成「暴雪中的夜晚。一隻黑狗突然衝出」的場景,並讓無人載具的演算法在這個虛擬平行宇宙中反覆試錯。這種「在夢境中訓練」的模式,讓AI能以低成本、高效率學會處理現實中罕見的長尾風險(Long-tail corner cases)。誰能打造出最逼真、物理規律最準確的虛擬訓練場,誰就能訓練出最聰明的駕駛AI。
台灣產業的機會點
展望2026,對於擁有強大半導體與資通訊供應鏈的台灣,這是一個從「賣零件」升級為「賣大腦」的轉折點。
隨著端到端模型的普及,車載電腦需要的不再只是普通的控制晶片,而是具備高算力的邊緣AI運算平台(如NVIDIA Orin或更高階的Thor等級晶片)。
工研院也在專訪中分享,感測器模組將需要更高的整合度與預處理能力。台灣廠商若能從單純的硬體代工,延伸至感測融合演算法的最佳化,甚至參與虛擬模擬場景的建置,將能在這波具身智能浪潮中佔據更有價值的生態位。
未來的無人載具,外表看起來可能還是那台車或那架飛機,但內在的靈魂已經改變。它不再是一台冷冰冰的機器,而是一個正在努力學習、適應並理解這個物理世界的智慧生命體。





